TanStack DB: Een client-first benadering van API’s

Het team van Tanner Linsley, de open source ontwikkelaar van TanStack Query, heeft de afgelopen maanden gewerkt aan iets nieuws: TanStack DB. Een ‘client-first store’ voor je API. Het belooft updates sneller te kunnen tonen door optimistische updates waardoor je hele frontend sneller aan moet voelen. Inmiddels is de library in Beta, binnenkort wordt versie 1.0 van deze library verwacht. In deze blog wil ik je kennis laten maken met TanStack DB en laten zien hoe het verschilt van zijn grote broer, TanStack Query.
Wat is TanStack?

Laten we helemaal bij het begin beginnen. Tanner Linsley is een frontend developer uit de Verenigde Staten, die op een gegeven moment zijn eigen boilerplate code begon om te zetten naar onafhankelijke libraries en later naar framework-agnostische pakketten. Dat bij elkaar is Tanners tech stack, en dat werd al snel TanStack.
De bekendste library is TanStack Query (voorheen React Query), met bijna 4 miljard NPM downloads, voor het managen van je asynchrone state. En een greep uit de andere libraries zijn:
- TanStack Table: Headless UI voor (data)tabellen
- TanStack Start: Full-stack (SSR React) Framework
- TanStack Virtual: Headless UI voor virtualiseren van elementen
- TanStack Router: Routing provider
- TanStack DevTools: DevTools voor alle TanStack Libraries samen
En dan natuurlijk nog waar deze blog over gaat: TanStack DB.
Wat is TanStack DB?
Voordat we verder gaan, is het goed om te begrijpen wat TanStack DB nu precies is. Zelf omschrijven ze het als ‘The reactive client-first store for your API’. Laten we die ondertitel eens ontleden.
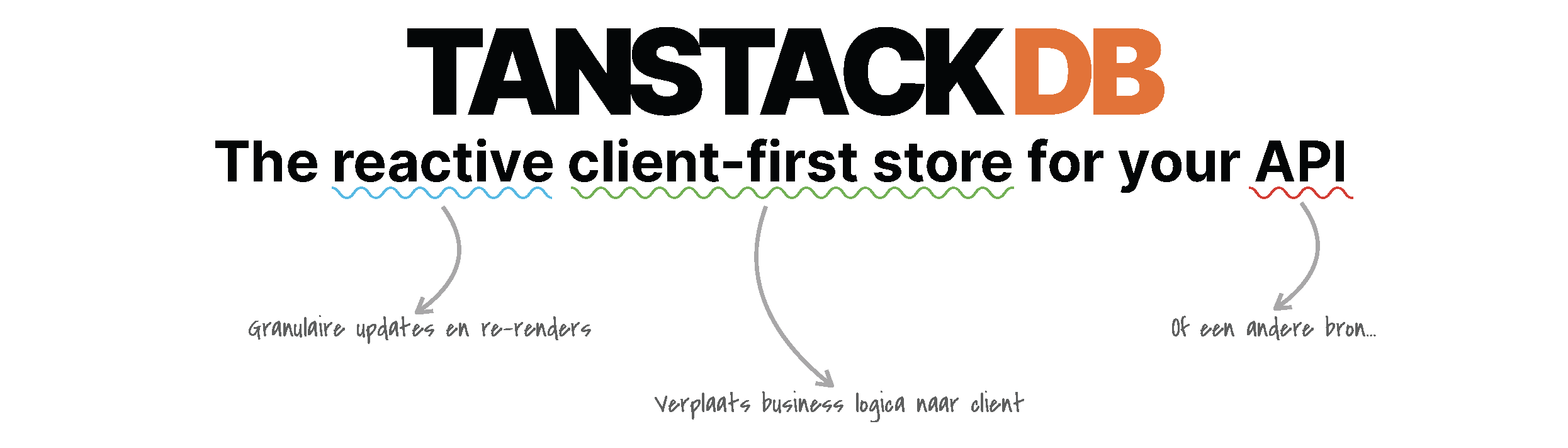
- API: Strikt genomen kan dit van alles zijn. Data kan dus afkomstig zijn uit een API, maar ook uit een lokale store, zoals LocalStorage of iets anders.
- Client-first store: Dit wil zeggen dat de lokale store leidend is op het moment dat deze beschikbaar is. Voor interacties, zoals mutaties, wordt primair de lokale state gebruikt. Hierdoor kun je sommige business logica verplaatsen naar de client.
- Reactive: Granulaire updates, door differential dataflow, en beperkte re-renders omdat slechts hetgeen dat gewijzigd is gepropageerd wordt.
Hoe werkt een update in TanStack Query?
In TanStack Query, kun je je asynchrone store updaten met een mutation, in de React implementatie gebruik je dan useMutation om je wijziging te versturen naar bijvoorbeeld je API. Zo'n mutation zorgt ervoor dat je gegevensstroom beter beheerd wordt, dat updates netjes achter elkaar verstuurd worden en zodat je zicht hebt op wat hun status is.
Wanneer de state van een checkbox wijzigt, zal de form-handler een mutatie aanmaken om de checked-state te wijzigen. Vervolgens praat de mutatie met de API om de gegevens aan te passen in de database.
De API geeft een succesmelding terug, en invalideert de Query state. Dat is waar de asynchrone state opgeslagen en beheerd wordt. Door het invalideren wordt een nieuwe fetch getriggerd om de data opnieuw op te halen uit de asynchrone state.
En voila! Het checkboxje is zichtbaar!
Hoe werkt een update in TanStack DB?
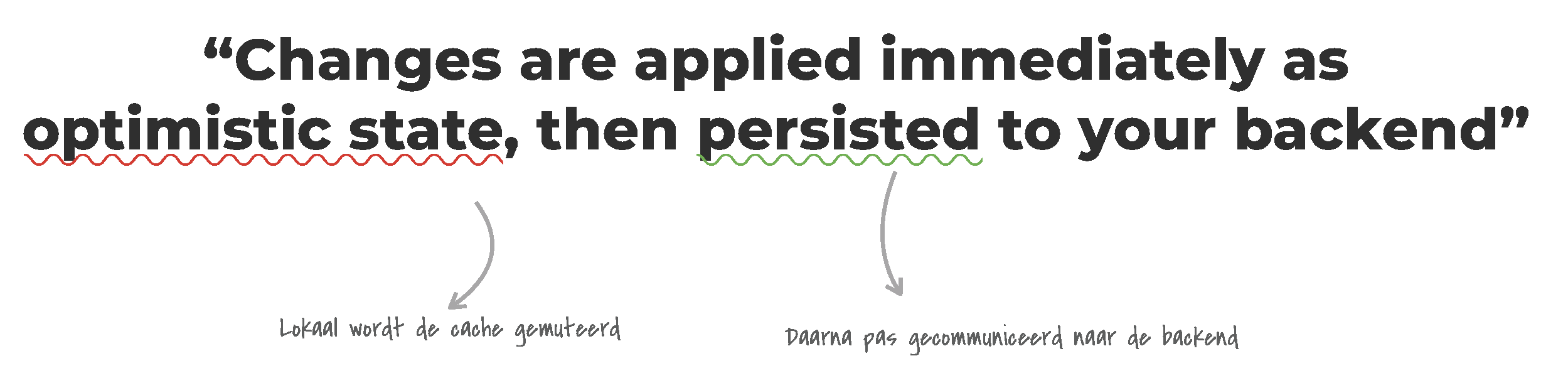
Laten we dan nu kijken hoe datzelfde proces werkt met TanStack DB. In het overzicht is direct al één verschil: in plaats van een Query hebben we nu een Collection. TanStack DB werkt vanuit collections, alle acties (HTTP-methodes) die je op een domein (API endpoint) kunt doen vallen onder een collection. Later duiken we daar wat dieper op in.
Wanneer je op een checkbox klikt, zal de formhandler een mutatie afroepen. Alleen gaat dat nu door het object te updaten, de implementatie van TanStack DB slaat nu als eerste de gewijzigde state op in de collections en past die toe in de UI. Binnen 1ms na het klikken is zo de checkbox op basis van de asynchrone state al zichtbaar.
Vervolgens, zodra er tijd voor is op de thread, wordt de patch uitgevoerd naar de API. Wanneer die succesvol was, komt het aangepaste object terug en wordt die overschreven in de collection. Nu is de client state weer gesynchroniseerd met de asynchrone state.
Omdat het een optimistic update is, kan het natuurlijk ook misgaan. Dus geeft de API een foutmelding? Dan wordt de wijziging ongedaan gemaakt en verdwijnt het checkboxje ook uit de UI.
TanStack Query
Dat waren, heel kort, de functionele verschillen tussen TanStack Query en DB. Maar om beter te begrijpen wat TanStack DB is, moeten we eerst even opfrissen wat TanStack Query is omdat TanStack DB daarop voortbouwt. TanStack Query is een library voor asynchrone state management, het helpt je met het beheren van gegevens binnen je applicatie. Bijvoorbeeld het resultaat van API fetches, updates en caches. Het bevat veel boilerplate voor het ophalen en muteren van deze ‘async state’, zoals de status van de state, cache, garbage collection en het invalideren en opnieuw ophalen van data.
Voordat we verder gaan, is het handig dat we iets hebben om over te praten, een voorbeeld. Het voorbeeld dat ik in deze blog ga gebruiken is een ‘leeslijst’, deze heeft categorieën (bijv. ‘blogs’ en ‘boeken’) en items met een ‘gelezen’ status.

DB is ontworpen met als doel om een aantal tekortkomingen uit Query te overbruggen. Stel je voor: je wil een API endpoint implementeren, deze heeft natuurlijk verschillende methoden: GET, POST, etc. Uitgaande dat alle vier HTTP methods voor CRUD geïmplementeerd zijn, zul je met Query al 4 hooks moeten implementeren om deze juist te verwerken.
Wanneer we gebruik maken van Query om onze endpoints te implementeren, zien we dat het al snel veel en hetzelfde wordt:
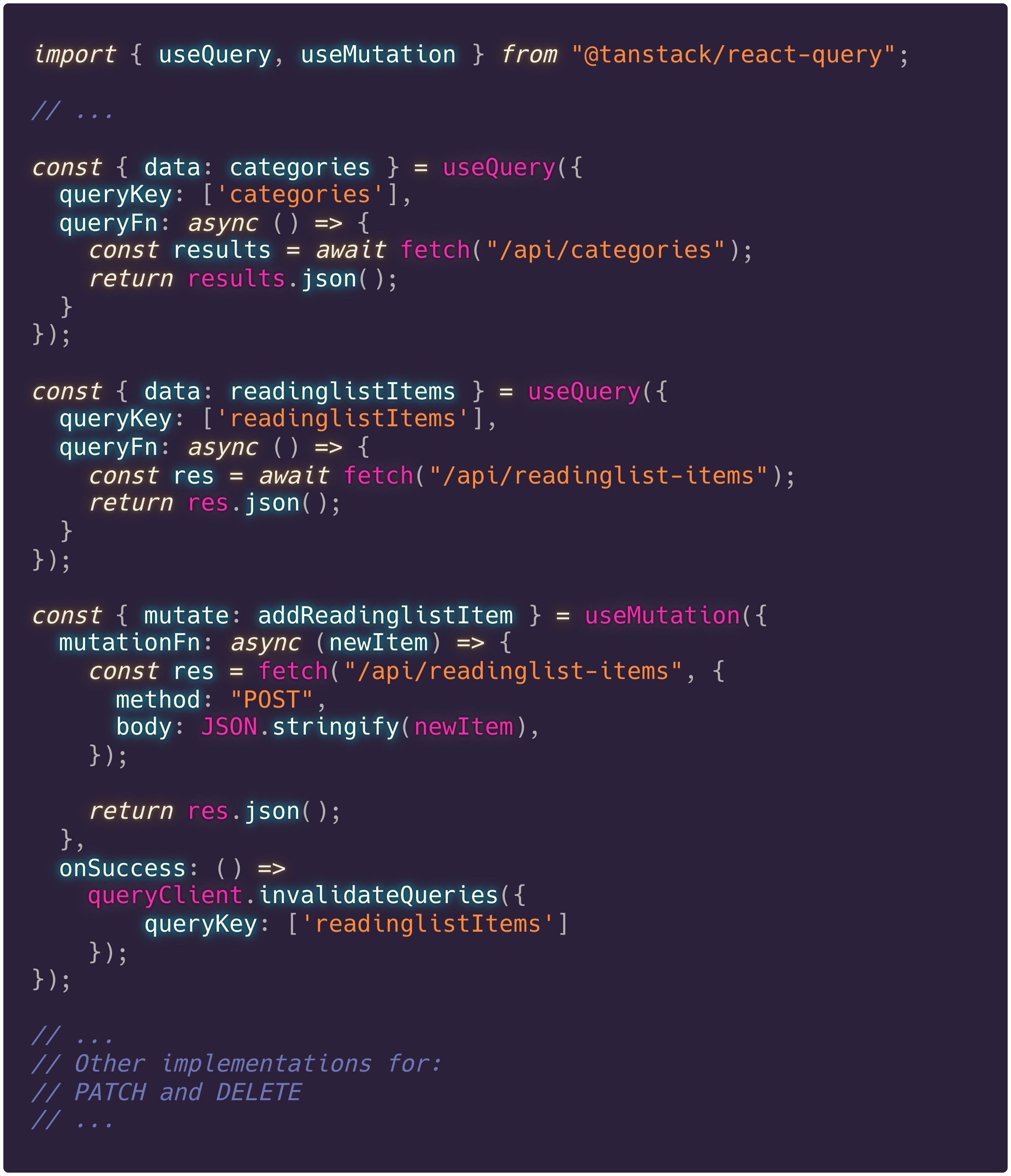
Dit is een implementatie die veel van ons gewend zullen zijn en ook helemaal niet gek vinden. Door Query te gebruiken kunnen we eenvoudig de data opnieuw ophalen wanneer we een nieuw item toevoegen, wordt de cache beheerd, voorkomen we dubbele calls, is de status van de queries inzichtelijk en nog veel meer.
We halen nu alle items in één keer op, voor deze kleine app is dat geen probleem. Maar wanneer de app groeit is dat wel iets waar we naar moeten kijken, daar komen we straks op terug.
Query is hier een prima oplossing, maar wanneer onze app gaat schalen zou het toch zo kunnen zijn dat we tegen problemen aan gaan lopen. Over tijd worden er meerdere implementaties van queries toegevoegd om een andere select toe te kunnen voegen, krijg je een wirwar aan queryKeys die niet meer te beheren zijn, of verschillende queries zodat ook geneste data wordt meegegeven, of zelfs handmatig gemerged. Kortom: relaties tussen verschillende queries, of modellen / domeinen, ontbreken. Ieder query resultaat, iedere queryKey, leeft in zijn eigen, geïsoleerde cache.
Terug naar de app. Stel je voor, om onszelf te motiveren iets af te strepen van de leeslijst, willen we alle items laten zien met een korte leestijd en die nog niet gelezen zijn van onze favoriete categorieën. Dat zouden we bijvoorbeeld in een select kunnen doen, maar logischer is waarschijnlijk met een filter:

Binnen de schaal van onze app, is dit prima. Maar hoe groter het aantal items wordt dat de API aan de client teruggeeft, des te meer er van de client gevraagd wordt aan performance. Daarbij werkt het alleen met de huidige implementatie, waarbij we zowel alle categorieën als alle leeslijst items in één keer ophalen.
In de toekomst voorzie ik wel een performanceverbetering aankomen waarbij we de leeslijst items alleen nog per categorie op gaan halen, en dan geeft deze manier te veel overhead. Dus tijd om de backend te vragen een extra endpoint toe te laten voegen waarop de filtering op de achterkant al afgevangen wordt, bijvoorbeeld GET /readinglist-items/short-reads.
Uit de praktijk zijn er meerdere redenen waarom dit misschien niet de meest gewenste optie is. Het is meer werk voor de backend, een extra API response dat moet worden onderhouden en afgestemd, in de frontend moet een extra query en queryKey onderhouden worden, de cache groeit met identieke data maar in een geïsoleerd blok, wanneer een item als gelezen gemarkeerd wordt moet dat ook gereflecteerd worden in deze query.
Al met al, best veel dingen om rekening mee te houden in deze kleine app. Deze complexiteit neemt alsmaar toe naarmate er meerdere nieuwe functies worden toegevoegd. Bijvoorbeeld tags op leeslijst items, of counters op categorieën.
Iedere nieuwe functionaliteit gaat gepaard met het synchroniseren van data, invalideren van caches en het voorkomen van onnodige rerenders in de app. Je kunt je nu afvragen of (en welke) businesslogica op de server zou moeten leven en welke in de client kán leven.
Op de meeste plekken waar je het internet gebruikt heb je het best wel goed: thuis met een rustig WiFi-netwerk, op kantoor aan de kabel, in de supermarkt op het 5G netwerk - in Nederland zijn we verwend. Maar ook hier zijn er plekken waar je internet misschien slechter is: op de boerderij van je ouders waar nog ADSL ligt en hooguit 3G bereik is, onderweg met de trein op de Veluwe. Kortom, ook hier is winst te behalen, en zeker wanneer je aan een internationale oplossing werkt met een bredere doelgroep wil je niet dat wanneer je op ‘gelezen’ drukt bij een item, dat het langer dan 200ms duurt totdat het vinkje daadwerkelijk verschijnt.
En dan: optimistic updates. Met TanStack Query kun je optimistic updates doen, maar dat vraagt wel van je om handmatig de cache te bewerken voordat je request uitgevoerd wordt. Als een eenmalige oplossing best te doen, een tweede keer ook nog wel. Maar als je meerdere queries hebt die je moet updaten, wordt het al snel veel overhead en steeds meer werk om te onderhouden. Helemaal wanneer je een nieuwe feature toevoegt, bijvoorbeeld een review-score op ieder gelezen item.
Mijn ervaring is dat wanneer je deze logica een aantal keer geschreven hebt in je applicatie, dat het logisch is om deze boilerplate te standaardiseren. En daarmee heb ik in combinatie met TanStack Query heel goede ervaringen. Toch blijft de complexiteit hoog wanneer je dit echt goed aan wil pakken en blijven er veel informatiestromen die je in bedwang moet houden.
Nu we goed geschetst hebben hoe dat dan werkt in een vrij eenvoudige app, kunnen we gaan kijken welke laag TanStack DB hier overheen legt om ons te helpen dit soort uitdagingen wat makkelijker te maken.
Maak kennis met TanStack DB
Eerder benoemde ik het al: TanStack DB wordt beschreven als een 'The reactive client-first store for your API’. Met ‘reactive’ bedoelen ze hier dat het state updates geeft wanneer gegevens wijzigen, maar bij TanStack DB gebeurt dat op een heel granulair niveau. Waardoor updates zo klein mogelijk blijven, en het opnieuw renderen van componenten wordt beperkt tot wanneer de data die je daadwerkelijk gebruikt, veranderd.
Om dat te bereiken breidt TanStack DB uit op TanStack Query met drie belangrijke principes:
- Collections
- Live queries
- Optimistische mutaties
Dus laten we die gaan bekijken.
1. Collections

Een collection is een ‘typed set of objects’ die kunnen worden gevuld met data. Afhankelijk van waar de gegevens vandaan komen, kan een collectie een vorm aannemen. Het kan bijvoorbeeld spiegelen aan het response van je API call of een tabel in de database.
Net als met TanStack Query kan de data uit een API fetch komen, en in de meeste gevallen zal dit ook zo zijn, maar is dat niet verplicht. Het kan bijvoorbeeld ook uit localstorage komen, of uit een sync engine.
Zoals we net benoemden is het een ‘typed set of objects’, we kunnen dus ook een type meegeven aan de data. Dit doen we met behulp van een schema, die kun je op verschillende manieren aanmaken, in dit voorbeeld gebruik ik de library Zod zoals die aangeraden wordt door de developers van TanStack DB. Op die manier kunnen we de volgende schema's definiëren:

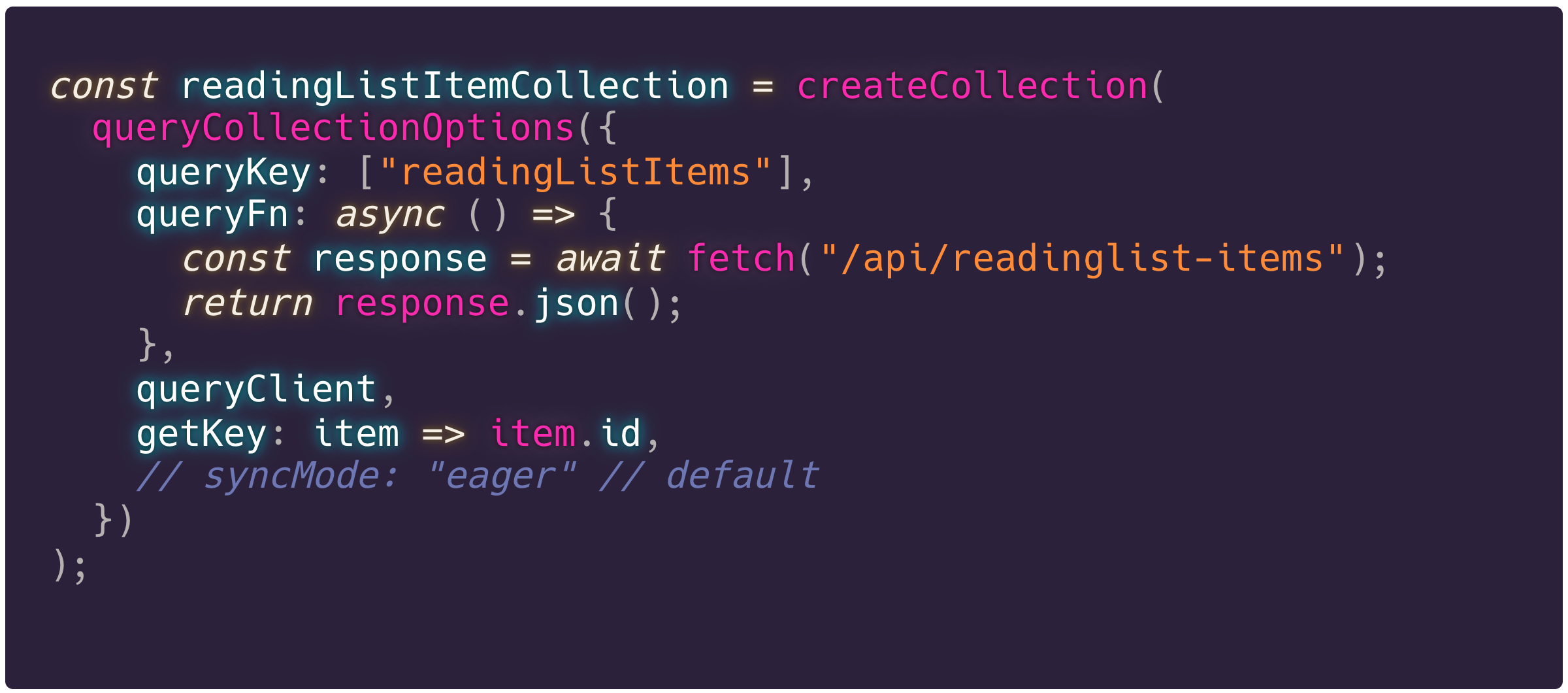
Nu we hebben vastgesteld wat de vorm van onze data is, kunnen we ook een collection gaan bouwen. Nu zijn er verschillende soorten collections: QueryCollections (voor TanStack Query), ElectricCollections (voor ElectricSQL) en nog veel meer. Wij beperken ons voor nu even tot de eerste, omdat we de vergelijking aan het maken zijn met TanStack Query. De queryCollectionOptions is de ‘factory’ voor het aanmaken voor een collectie die data fetcht van een remote, zoals onze API.
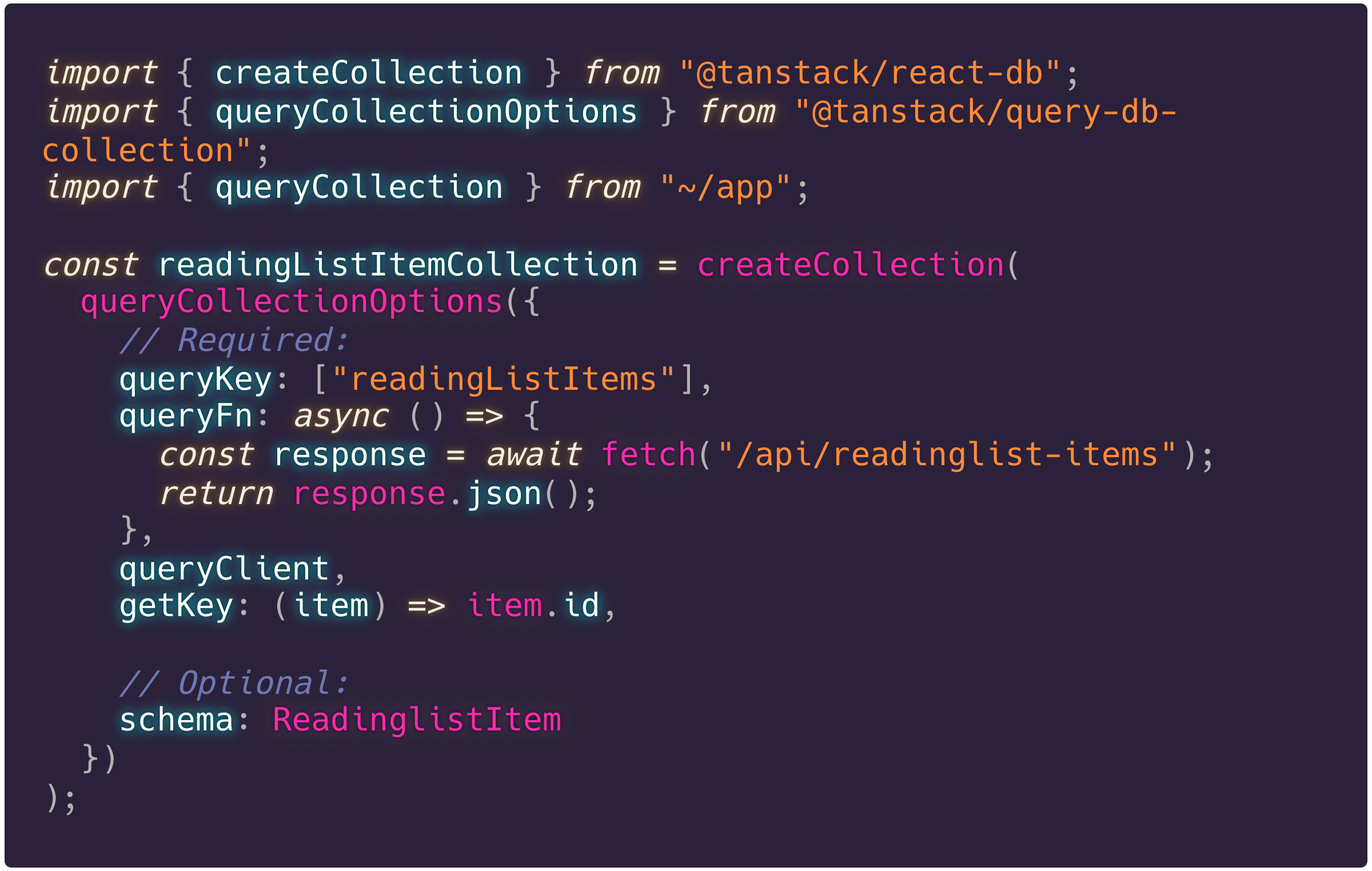
Het schema is hier dus optioneel, maar wel aan te bevelen.
2. Live Queries
We hebben nu een collection aangemaakt, dat is waar de data bewaard wordt. Je kunt het zien als je store, global state of cache. Om daar data uit te halen gebruik je een live query, en deze zijn reactive. Wanneer de onderliggende data op een manier verandert waardoor het resultaat beïnvloed wordt, wordt het resultaat geüpdatet en geretourneerd uit de query. Daardoor wordt dan een re-render afgeroepen.
Een live query heb je nodig omdat, anders dan bij TanStack Query, je het resultaat kan filteren, transformeren en samenvoegen uit meerdere collecties. Nu klinkt dat intensief, maar door een implementatie van ‘differential dataflow’ zijn ze razendsnel. Je kunt meerdere honderdduizenden regels filteren in minder dan 1ms.
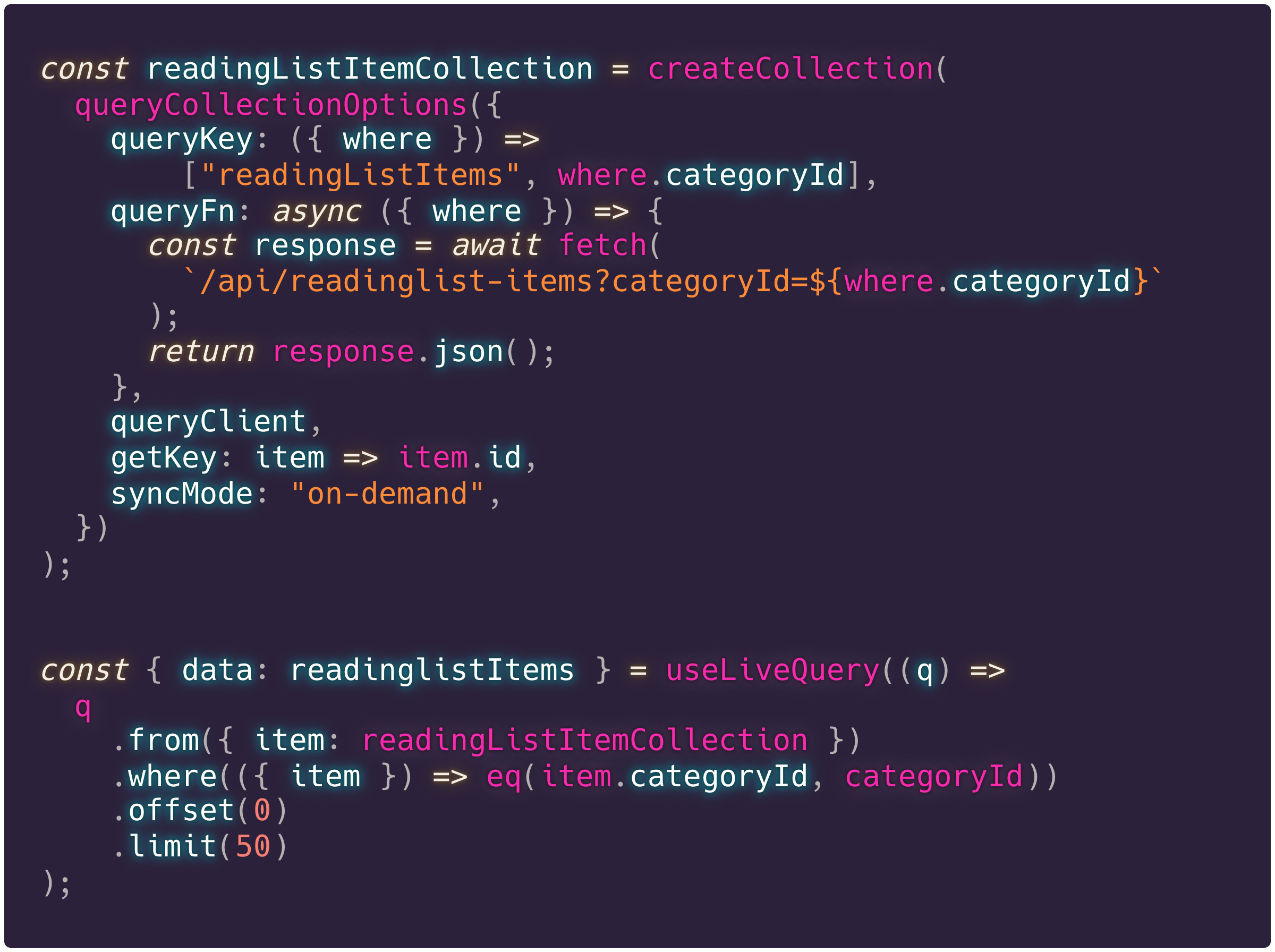
Dat filteren, transformeren en samenvoegen gaat op een manier die erg op SQL lijkt, over de data uit 1 of meerdere collecties. Laten we eens kijken hoe dat er uitziet wanneer we de leeslijst items ophalen voor de geopende categorie.

Live queries laten je dus genormaliseerde data in collecties inladen, en die kun je denormaliseren door middel van queries en zelf joinen vanuit verschillende databronnen.
Stel je voor, dezelfde functie implementeren die we eerder hadden. Die waarmee we kunnen zien welke korte ongelezen leeslijst items in een categorie zitten die favoriet is. Dan zou dat er zo uit kunnen zien:

Niet alleen is dat op deze manier mogelijk zonder backend wijzigingen, nieuwe endpoints, of dubbele queries. Alle problemen omtrent caching, en live updates zijn ook direct opgelost. Nu gaat deze manier er nog wel vanuit dat alle categorieën en leeslijst items in één keer opgehaald worden.
3. Optimistische mutaties
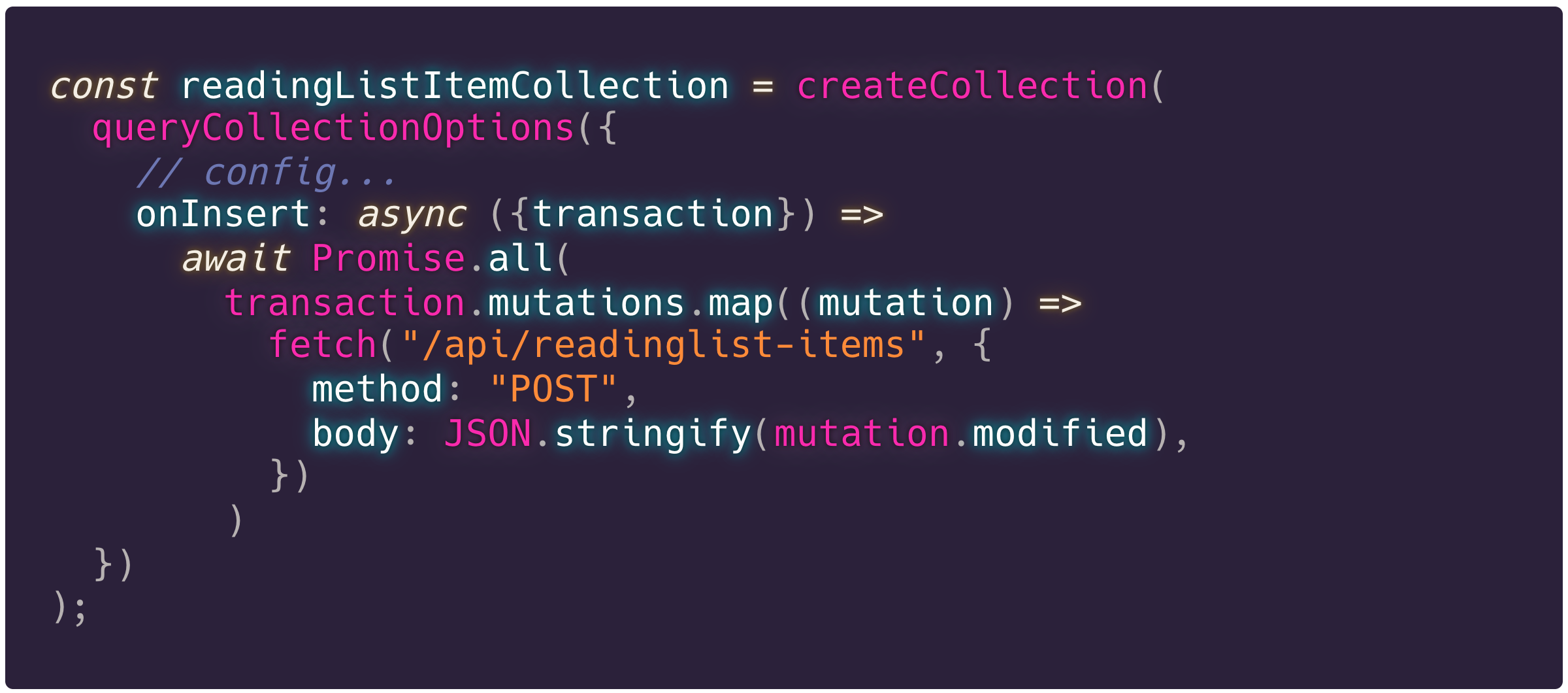
De queryCollection die we hebben aangemaakt ondersteunt deze altijd de GET functionaliteit. Collections ondersteunen ook handlers voor insert, update en delete. Om dat af te vangen, kun je de onInsert handlers (onInsert, onUpdate en onDelete handlers) toevoegen aan de collection. Hier geldt dus weer, je voegt het 1 keer toe, en vervolgens kun je het op een logische manier gebruiken op alle plekken waar de collection gebruikt wordt.
Dit is hoe de onInsert methode eruit zou zien in onze collectie:
En bij het aanmaken hoeven niet meer te doen dan:

Naast dat het request naar de API wordt uitgevoerd om deze te updaten, wordt het item direct optimistisch toegevoegd aan de collection. Hierdoor wordt het direct gereflecteerd in de state. Wanneer de API daadwerkelijk is geüpdatet, wordt de collection nog eens gesynchroniseerd. Is het mislukt? Dan wordt de update automatisch teruggerold.
Deep Dive
We hebben nu gezien wat TanStack DB in de basis kan en biedt. Maar er zijn nog een paar dingen die ik graag wil benoemen voordat we er een punt achter zetten.
Sync Modes
Tot nu toe hebben we steeds alle data opgehaald in een collection. De queryFn verwacht dan ook dat alle data in één keer teruggegeven wordt. Wanneer je de default syncMode (= eager) gebruikt, moet data dan ook in één keer beschikbaar zijn.
Soms werkt het echter niet zo, of is het simpelweg niet logisch om alle data in één keer van de remote op te halen. Bijvoorbeeld wanneer het aantal records te groot wordt, het response te groot is - of te langzaam. Met sync modes kun je beïnvloeden hoe en hoeveel data vanuit de backend naar de client gesynchroniseerd wordt.
Op hoofdlijnen zijn er drie sync modes:
- Eager (default)
- On-demand
- Progressive

Bij eager sync wordt de volledige dataset opgehaald zodra de collectie begint met synchroniseren. De collectie wordt pas als ‘ready’ gemarkeerd wanneer alle records zijn binnengekomen, dit gebeurt in één keer.
Dit is het gedrag dat we tot nu toe impliciet hebben gebruikt:
Alle leeslijst-items staan nu lokaal in de collectie. Live queries filteren gaat hier dan ook volledig in de client. Deze wijze kies je wanneer de dataset klein is, volgens TanStack zelf is dat minder dan 50K records aan genormaliseerde data. Voordeel is dat je hiermee razendsnel lokaal kan filteren, door de implementatie van differential dataflow.
Maar die snelheidswinst behaal je pas zodra de data initieel is binnengehaald, en hoe groter de dataset is, hoe langer het duurt voordat je die snelheidswinst kunt gaan behalen. Daarbij kan het zo zijn dat je initieel heel veel data over de lijn moet sturen.

Bij on-demand sync draait TanStack DB het model om. In plaats van eerst syncen en dan filteren, wordt data alleen gesynchroniseerd wanneer een live query daar expliciet om vraagt.
Deze variant kun je goed gebruiken wanneer je dataset groter is, je minder data over de lijn wilt sturen en een minder krachtige client verwacht. Het nadeel is dat het iets complexer is, en dat er voor ieder filter een nieuwe call moet worden gedaan naar de API, wat waarschijnlijk langzamer is.

Progressive sync combineert beide strategieën:
- Eerst wordt alleen de subset geladen die nodig is voor actieve live queries
- Ondertussen synchroniseert TanStack DB de volledige dataset op de achtergrond
- Zodra die klaar is, wordt atomair overgeschakeld naar de volledige collectie
Voordelen:
- Snelle eerste render
- Uiteindelijk volledige dataset lokaal beschikbaar
- Geschikt voor collaboratieve of data-intensieve apps
Nadelen:
- Complexere synchronisatie
- Meestal overkill voor standaard CRUD-apps
Differential Dataflow
Zoals al benoemd maakt TanStack DB gebruik van differential dataflow voor het uitvoeren van optimistische mutaties.

De implementatie die TanStack DB gebruikt, d2ts, zorgt voor incrementele updates. Dus in plaats van dat de volledige collection bewerkt wordt, worden alleen de delta's bijgehouden. De output is dus de som van de wijzigingen. Daardoor is het dus heel snel.
Zonder differential dataflow wordt na een manuele update de volledige query herberekend. Of, als je handmatig een optimistische update zou doen met TanStack Query, doorloop je de hele state om een item aan te kunnen passen. De tijdscomplexiteit is hier dus O(n). En wanneer je een grote collectie hebt, kan dit zo'n 100ms duren voordat de aanpassing zichtbaar wordt.
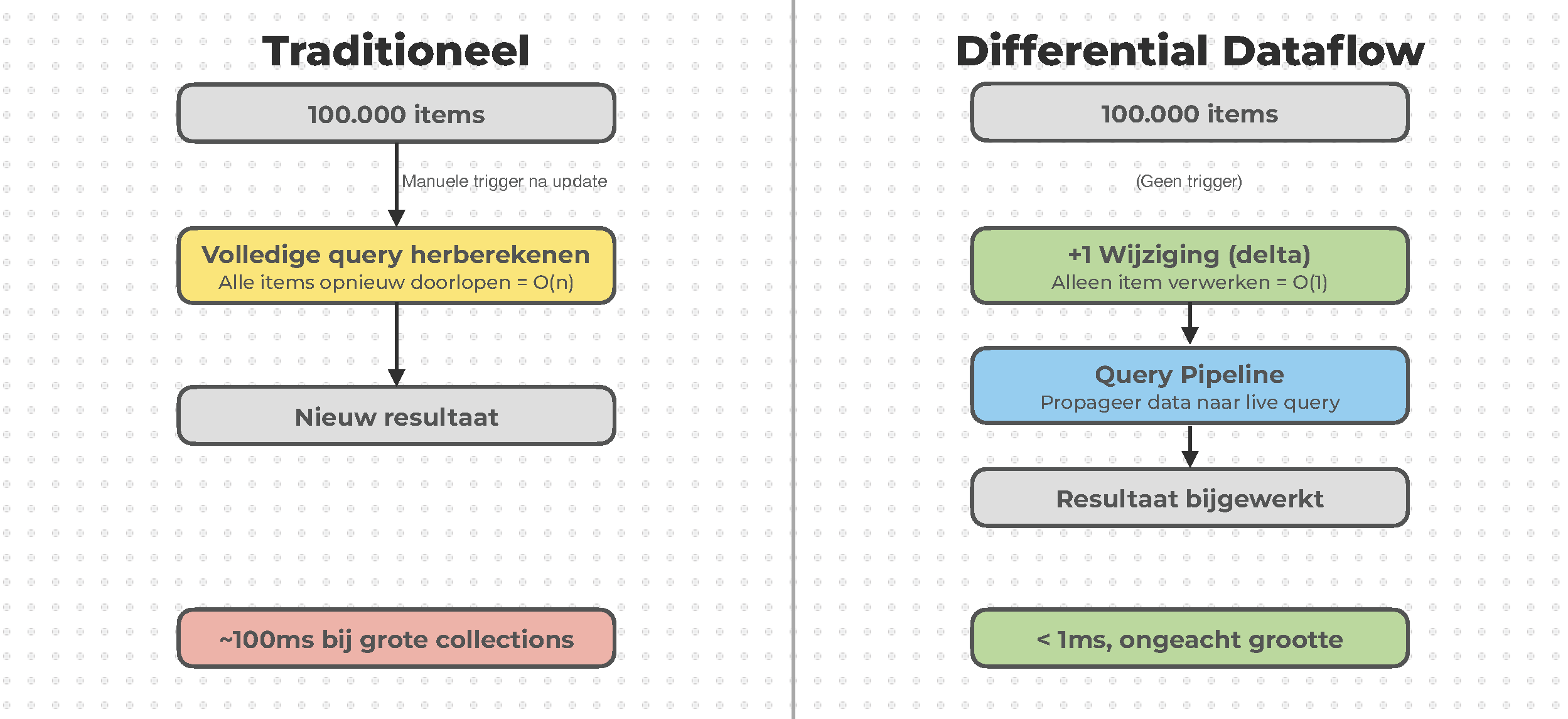
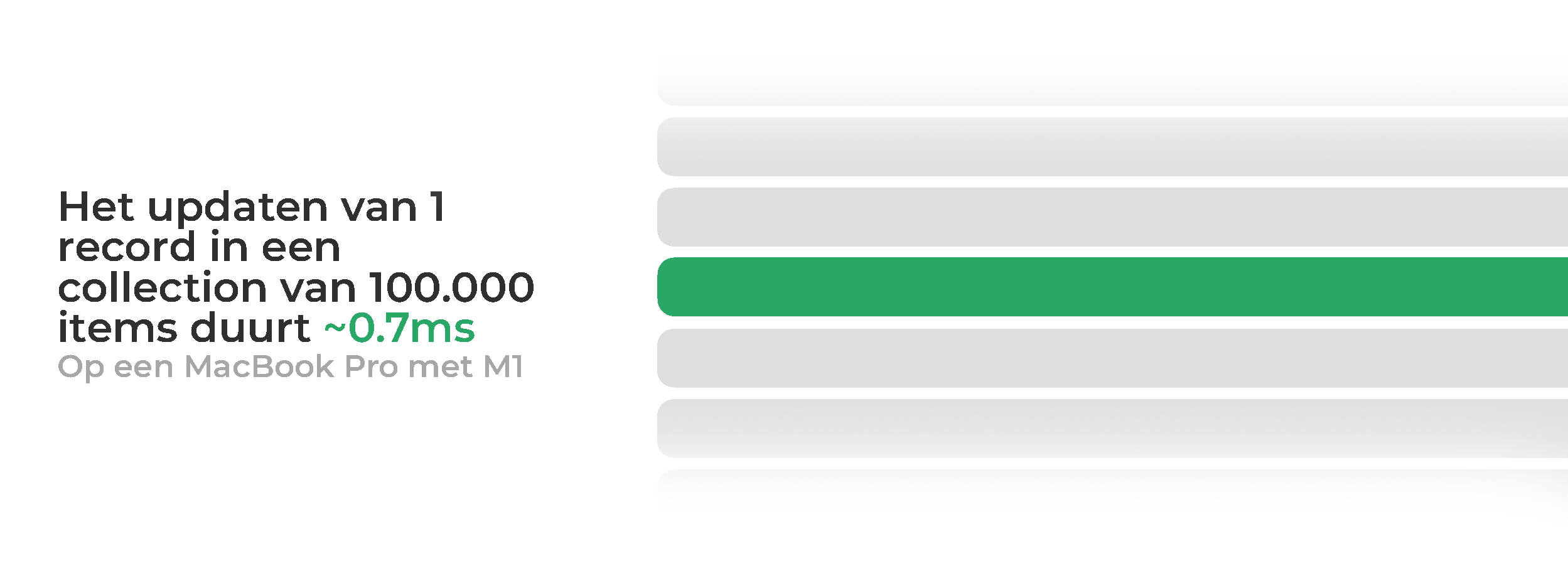
Door differential dataflow te gebruiken gaat dit zonder manuele trigger. De wijziging die erbij komt wordt als delta toegevoegd en loopt door een 'query pipeline', die de data propageert naar boven. En dan is het resultaat direct bijgewerkt, met zo min mogelijk rerenders: namelijk alleen wanneer de data gebruikt wordt. Dat is klaar binnen 1ms.
Wrapping up
Dan om af te ronden heb ik nog een paar bevindingen. Zeker geen waarheid, maar iets om mee te nemen mocht je geïnteresseerd zijn.
- Een logisch vervolg op TanStack Query, absoluut geen vervanging
- Minder boilerplate bij grotere applicaties
- Minder backendcapaciteit nodig door genormaliseerde data
- Meer grip op de endpoints door het gebruik van collections
- Duidelijke client-first strategie. Opinionated, maar wel optimistisch.

En dat brengt ons aan het einde van deze blog. Je weet nu iets over collections, joins, query language, optimistic updates, differential dataflow en meer. TanStack DB is nu in Beta, dus al goed te gebruiken mocht je dat interessant vinden.
Deze blog is tot stand gekomen op basis van de documentatie van TanStack DB en geïnspireerd door de blog van Frontend at Scale.

























