Web Components 101 – Part 5: Scaling up!
Web components. Een term die steeds vaker terugkomt. Maar net als veel andere tech-hypes lijkt de belofte van web components nog niet waar gemaakt te zijn. Of toch wel? Web components zijn al lang niet meer zo obscuur als een paar jaar geleden. Alleen in Nederland al gebruiken een aantal grote organisaties ze al meerdere jaren in productie. Steeds meer teams herkennen de meerwaarde van de onafhankelijkheid die webstandaarden met zich meebrengen.
Echter vind ik dat ze nog niet altijd in even goed daglicht staan! Daarom neem ik je de komende weken mee in het gedachtegoed, de basics, het ecosysteem, en laat ik zien hoe je een volwaardige frontend applicatie kan bouwen met web components.
Dit is het vijfde deel van deze blogpost serie over Web Components. Heb je deel vier nog niet gelezen? Klik hier om hem alsnog te bekijken.

Hoe bouw je nou een grote en complexe frontend op basis van web components? Het korte antwoord: niet anders dan met andere frontend technieken! Alle bekende frontend frameworks zijn gebaseerd op hetzelfde basisprincipe: scheiding op basis van componenten. Natuurlijk: de details kunnen verschillen. React beweegt naar een toekomst waar Hooks de primaire manier zijn om state te delen tussen componenten. Angular zet juist volledig in op SOLID-principes, en deel je state en logica met behulp van services, geïnjecteerd met Dependency Injection.
Dus. Let’s go bigger. Van hello world naar volwaardige applicatie. Waar begin je eigenlijk mee? Dat begint natuurlijk met npm install redux het verzamelen van de eisen! En dan niet alleen de eisen vanuit de business. Maar juist die van je collega’s zijn heel waardevol voor het opzetten van een nieuwe applicatie.
Het Fundament
Er zijn veel verschillende aspecten aan een frontend applicatie die belangrijk zijn. Afhankelijk van de organisatie en de doelgroep kunnen ze enorm specifiek zijn. Maar ik vind dat vrijwel alle aspecten te definiëren zijn in vier categorieën. Ik noem ze de vier pijlers van een solide frontend architectuur. Ze zijn toepasbaar op alle frontend applicaties.
De vier pijlers van een solide frontend architectuur:
- Modulariteit
- Testbaarheid
- Developer Experience
- User Experience
Laten we even op elke pijler inzoomen.
- Modulariteit
Dit omvat alles rondom de structuur en kwaliteit van de codebase. Voor mij is kwaliteit een hoge mate van herbruikbaarheid. Het liefste is zoveel mogelijk code multi-inzetbaar, zodat er zo min mogelijk duplicatie is. Wanneer je herkent dat je twee of drie keer hetzelfde doet, dan is het misschien tijd om er een generiek stukje code van te maken.
Echter, moet hier een goede balans in zitten: er is niks zo verwarrend als een codebase waar tachtig soorten base classes bestaan, én componenten herbruikbaar zijn gemaakt tot op het punt dat ze maar één regel HTML uitspugen. Daarom is het belangrijk om van tevoren goed na te denken over deze pijler: hoe generiek willen we onze code hebben, en waar zetten we de grens tussen generiek en begrijpelijk?
Om de modulariteit van de codebase te verhogen zijn er twee dingen belangrijk: een technische visie, en een continue feedbackloop in de vorm van code reviews.
Het is goed om met een groepje developers (minstens) elke maand even een review-sessie te houden om te kijken hoe de applicatie er uit ziet, en waar er pijnpunten, hacks en andere slordigheden zich opstapelen. Vraag elkaar vervolgens waarom deze slordigheden zo zijn gebouwd, en hoe dit in de toekomst kan worden opgelost. Pak dan bijvoorbeeld de top drie actiepunten op en plan ze in. Zo kun je er meteen werk van maken en de codebase elke keer nét een beetje beter te maken.
Het liefste reviewen developers elkaars code. Voor kleine teams kan het zijn dat iedereen een PR bekijkt, en voor grotere teams kan het zijn dat er een centraal groepje developers in shifts alle PR’s nakijkt. Doordat iedereen bezig is met het bekijken van de codebase die als maar groter wordt, krijgt iedereen mee wat er actueel is, maar ook wat er minder handig is gebouwd. Het geven én ontvangen van feedback is een win-win situatie voor iedereen. En op de lange termijn geeft het iedereen een verantwoordelijkheidsgevoel voor de kwaliteit van de codebase.
Als je bewust bezig bent met het reviewen tijdens het ontwerpen en bouwen van de applicatie zal je merken dat dit een constante machtsstrijd is tussen deze twee kampen. Continu worden twee tegenovergestelde persoonlijkheidsaspecten van je aangesproken: perfectionisme en pragmatisme. Maar ondanks dat het soms voelt als een uphill battle zul je op lange termijn merken dat het development team hier uiteindelijk zelf een goede balans in weet te vinden. Dat mensen op het internet een bepaalde manier 'de beste manier' vinden zul je altijd houden. Het belangrijkste is dat het voor jouw team goed werkt.
- Testbaarheid
Een frontend applicatie ontwikkelen zonder unit tests is echt niet meer van deze tijd. Frontends zijn in de afgelopen jaren zo complex geworden dat ze voor een enkele developer niet meer volledig te begrijpen zijn. En wat als die ene developer weg gaat bij je bedrijf, wie weet dan nog hoe die ene feature hoort te werken?
Daarom is het belangrijk om te uit te denken hoe jouw codebase moet worden getest, en tot welk niveau. Er zijn namelijk nogal wat niveaus waarop je een frontend kan testen:
- Visual Regression Testing
- Accessibility Testing
- Snapshot Testing
- Unit Testing
- Integration Testing
- End-to-End (E2E) Testing
- …en er zijn er nog veel meer!
Wat zijn voor jou de allerbelangrijkste zaken om gegarandeerd goed te hebben staan? Hecht je bijvoorbeeld heel veel waarde aan een pixel perfect applicatie? Dan kan je extra tijd besteden aan Visual Regression- en Snapshot-testing. Als je wil dat het kopen van een product gegarandeerd blijft werken na elke change, dan kan je dat het beste afvangen met een E2E-test. Zo is er voor elke wens een bijpassende stijl van testen. Welke zijn voor jou toepasbaar?
- Developer Experience
Blije developers schrijven goede code. In theorie. Maar het helpt écht om een codebase te hebben met een goede Developer Experience, de DX.
Even een voorbeeldje van waarom de DX zo belangrijk is. De vorige pijler ging over het testen van de applicatie. Wellicht zag je de lijst van testvormen en dacht je: Hoe meer hoe beter. Maar wat als ik je vertelde dat méér testen zorgen voor een slechtere DX? Als je namelijk 95% of een hogere coverage hebt van alle testvormen, dan zal je ervaren dat je voor elke kleine change misschien wel tien tests moet fixen. En niet alleen unit tests: je zal de snapshots moeten updaten, de integratietest moeten aanpassen en de E2E-test opnieuw moeten bekijken of die nog wel de goede stappen doorloopt. Continu context switchen dus.
Daarom kijk je naar de Developer Experience. Niemand wil werken bij een bedrijf waar je na elke style-change nog een uur lang tests moet updaten. Maar dit is niet het enige waar je tijd aan zal moeten besteden om de Developer Experience op een hoog niveau te krijgen.
Denk bijvoorbeeld aan de volgende zaken die het leven van een developer makkelijker maken:
- Automatische linting (& fixing) tijdens het aanmaken van commits;
- Een makkelijke manier om de applicatie te draaien zonder lokaal twintig microservices te moeten opstarten;
- Een makkelijke manier om alle states van verschillende componenten in isolatie te bekijken, bijvoorbeeld met Storybook;
- Behulpzame utility classes, functies en decorators om veelvoorkomende stukjes code (zoals logging en analytics) nét even wat makkelijker te schrijven;
- Een snelle development server met Hot Module Replacement om je wijzigingen direct in de pagina te zien;
- Een duidelijke databank met testaccounts voor allerlei soorten users met allerlei rollen;
- Inzicht in de gezondheid van de TAP-omgevingen door middel van (error) logging, analytics en performance statistieken;
- Een snelle pipeline met duidelijke feedback als er dingen fout gaan;
- Documentatie over features, keuzes en structuren die niet vanzelfsprekend zijn.
Ik kan nog wel vijftig punten benoemen die belangrijk zijn om de Developer Experience hoog te houden, maar ga hiervoor ook in gesprek met de stakeholders: de ontwikkelaars. Welke tools hebben zij nodig om hun werk zo optimaal mogelijk uit te kunnen voeren? En van wat voor verbeteringen worden ze écht blij? Want de eindgebruikers zijn niet de enigen die de applicatie gebruiken. De developers gebruiken hem ook, en zij doen het wel tientallen uren per week.
- User Experience
Developers zijn echter niet de enige die je tevreden moet houden. Uiteindelijk maken we software voor de eindgebruikers. En die hebben ook wel wat eisen en wensen. Daarom is de laatste pijler de User Experience (UX): de manier hoe de gebruiker de applicatie ervaart.
Bewust of onbewust hebben gebruikers namelijk nogal wat (technische) eisen aan jouw frontend applicatie. Ze verwachten bijvoorbeeld dat de applicatie snel is. Dat ze hem kunnen gebruiken in hun favoriete browser. En dat ze met bekende shortcuts taken kunnen uitvoeren binnen jouw applicatie, zoals met tab door velden springen van een formulier. Of dat ze met CTRL/CMD+P de pagina op een mooie manier kunnen uitprinten.
Deze zaken tellen op tot een groter geheel: de technische eisen over hoe jouw applicatie functioneert. En deze vertalen weer direct door naar code, want die ondersteuning voor Internet Explorer komt er niet tenzij je dat inbakt in de build tooling. En als je wil dat je frontend binnen een halve seconde wordt ingeladen zul je toch moeten kijken naar een agressieve manier van CSS-inlining en resource caching.
En soms staan deze eisen haaks op de pijlers van modulariteit, testbaarheid en developer experience. Soms zal je namelijk een concessie moeten doen op de andere pijlers om uiteindelijk een fijnere User Experience aan te kunnen bieden aan de gebruikers. Door bijvoorbeeld de codebase minder generiek te maken, zodat jouw Shared-bundle niet meerdere Megabytes groot wordt. Onderzoek daarom goed wat de User Experience moet worden van jouw frontend applicatie. Balanceer deze eisen en wensen goed met de andere pijlers, want dan krijg je uiteindelijk een mooi geheel dat voor iedereen fijn werkt.
Dus. Let’s go big. Hoe ziet dit er in de praktijk uit?
Laat ik allereerst even zeggen dat er geen één standaardarchitectuur perfect aansluit bij de wensen en eisen van jouw specifieke applicatie. Ik heb een paar diagrammen uitgewerkt met hoe een frontend applicatie er uit kan zien, maar zie het meer als een inspiratie dan een blauwdruk.
We beginnen met een enkele standaard frontend applicatie. Dit is een veelvoorkomende structuur voor het MKB: een enkele applicatie voor bijvoorbeeld een SaaS of B2B pakket die in een enkele codebase wordt gebouwd. Deze applicatie heeft alles: routing, state management, business functionaliteit en alle standaardcomponenten. Bij een applicatie als deze is het belangrijk om een duidelijke hiërarchie af te spreken. Daarom heb ik gekozen om de structuur op te delen in een aantal standalone onderdelen.
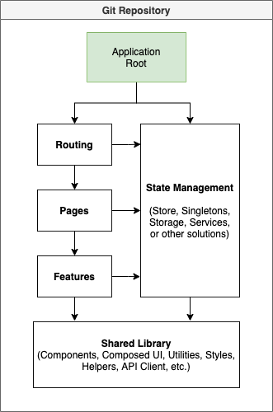
Deze hiërarchie zie je duidelijk terug in het diagram. Het begint allemaal bij de Application Root. Dit is eigenlijk gewoon de eerste component dat wordt ingeladen op de pagina, en ook dezelfde lifecycle heeft als de webpagina: opgestart wanneer de gebruiker op de pagina komt, en stopt wanneer de gebruiker weggaat. Dit is vaak de component die de routing configuratie bevat, en de status van authenticatie beheert, veelal via een stukje state management.
State management is het centrale deel van deze applicatie. Ik heb de implementatie bewust open gelaten: als jij graag werkt met een store oplossing kan je dat hier heel goed op aansluiten. Maar als je bijvoorbeeld gaat voor een service-gerichte oplossing dan kan je dat ook kwijt in dit model. Zolang verschillende onderdelen van de applicatie maar data kunnen opslaan, data kunnen wegschrijven en eventjes kunnen ontvangen wanneer er iets belangrijks gebeurt.
Naast state management staan drie modules: routing, pages en features. De hiërarchie hierin is belangrijk. Routing bevat een grote configuratie met business logica over wie waarbij mag. De routing configuratie laadt pagina’s in. Deze pagina’s zijn vrij kale componenten die één of meerdere features aan elkaar knopen. Ook zijn de pagina’s bijvoorbeeld verantwoordelijk voor het uitlezen van URL-parameters. Deze data kan dan worden meegegeven aan de volgende laag: de features.
Features zijn componenten die verschillende basis elementen als knoppen en formulieren combineren tot een stukje interactie voor de gebruiker. Denk bijvoorbeeld aan een formulier met validaties en een submit-knop. Dit is een verzameling van verschillende basiselementen, met een stukje business logica er aan vast.
De reden dat ik features los heb getrokken van de pages is in het kader van modulariteit: wanneer je vanuit de routing-configuratie direct een feature inlaadt als pagina, dan zal je merken dat er altijd wat extra logica insluipt die er voor zorgt dat een feature minder herbruikbaar is. Bijvoorbeeld specifieke styling voor de positie op de pagina en het uitlezen van URL-parameters. Terwijl je op een andere pagina wellicht dezelfde feature wil gebruiken, maar dan als deel van een flow met andere styling er omheen. Dus voorkom jezelf de hoofdpijn en denk bij een nieuwe pagina met features vooral na: wat is de essentie van de feature, en wat zijn de input parameters die nodig zijn om de feature op te starten? Als je deze input parameters in het page-component kan verzamelen en meegeeft aan de feature, dan kan je op een andere pagina dezelfde feature gebruiken met andere input parameters.
De Routing, Pages & Features modules praten allemaal tegen de State Management oplossing aan. Zo zal de routing module veelal data opvragen over of de gebruiker wel is ingelogd, en bij een bepaalde pagina mag. Pages kunnen bijvoorbeeld data opvragen uit de state om mee te geven aan de features op de pagina. Deze features kunnen dan weer data wegschrijven via state management naar een API. Omdat state management oplossingen vaak een manier hebben om events of lifecycle hooks af te trappen wanneer er data wijzigt, kan er op elk niveau van de applicatie worden geluisterd naar de state. Als een user de logout-feature gebruikt om uit te loggen, kan de router bijvoorbeeld de gebruiker doorverwijzen naar de homepage.
Tot slot is er de Shared Library. Dit is een grote verzamelbak van herbruikbare logica. Alle styling en basiscomponenten staan hier in; knoppen, pop-ups, input-velden en nog meer. Ook generieke utilities en andere helpers kan je hier neerzetten; download-utilities, basis form validatie, localstorage-helpers en ga zo maar door. In principe is dit de dumping ground van alles wat generiek is. Belangrijk hierbij is dat je zorgt voor een duidelijke mappenstructuur en documentatie binnen de shared library. Zo kunnen developers makkelijk vinden wat ze zoeken, en door de documentatie weten ze direct of het generieke stukje code ook voor hun situatie geschikt is. Nu hoef je echt geen dikke Confluence-pagina’s bij te gaan houden van je shared library. Zorg er voor dat alle bestanden in de shared library bovenaan de klasse of het bestand een korte samenvatting heeft van wat er in zit. Als je dit doet met JSDoc-commentaar heb je direct ook in je IDE de uitleg staan als je op een klasse of functie hovert. Dat is DeveloperExperience++.
Het voorbeeld hierboven is een standaardarchitectuur die voor veel applicaties geschikt is. Met een duidelijke hiërarchie en een goed fundament in de vorm van een shared library kan je hier kleine tot hele grote applicaties mee bouwen. En omdat hij in de basis erg simplistisch is kan je uitbreiden waar nodig. Bijvoorbeeld door een dedicated design system toe te voegen in een losse module, gevuld met basiscomponenten en goede documentatie. Maar op gegeven moment zal je toch meer scheiding moeten aanbrengen om modulariteit te bereiken. Daarom heb ik nog een paar voorbeelden voor hoe je nóg grotere frontends kan opzetten.
Let’s go even bigger.
De standaardarchitectuur hierboven is een goede basis voor de meeste applicaties. Maar wat als je meerdere frontend applicaties hebt die dezelfde componenten moeten gebruiken? Een klanten- en beheerportaal bijvoorbeeld. Je kan het in dezelfde codebase proppen, maar op het moment dat je bijvoorbeeld nog een derde rol toevoegt kan het nogal een if-else soup worden. Op dat moment kan je gaan kijken naar het opsplitsen van de codebase in verschillende packages.

We beginnen even met een simpel voorbeeld. Twee of meerdere applicatie die dezelfde generieke componenten en andere utilities gebruiken. Als je inzoomt op applicatieblokken heb je eigenlijk de standaardarchitectuur die ik eerder heb doorgenomen: minus de shared library. Deze kan je opsplitsen in een eigen losstaande package. Er zijn meerdere manieren hoe je dit opsplitsen kan bereiken.
NPM Packages of een Monorepo?
De meest veilige manier van opsplitsing is door van elke package een echte NPM Package te maken vanuit een losse Git repository. Zo is er geen enkele manier waarop Application 2 naar Application 1 kan verwijzen. Of de shared library naar een van de applicaties. Deze manier van opsplitsen brengt echter veel complexiteit met zich mee: elke package heeft een eigen CI/CD configuratie, en je zal een gesloten NPM Repository moeten hosten met bijvoorbeeld Azure Artifacts of Nexus Repository Manager. Developers moeten dan weer een custom repository configureren in hun lokale ontwikkelomgeving, wat weer zorgt voor een complexere set-up voor nieuwe collega’s. Ook moet je nadenken over de versionering van NPM packages, en het proces van het uitrollen van nieuwe versies met patches en breaking changes. Niet zo’n fijne DX dus.
Het alternatief hierop is het gebruiken van een monorepo. Dit is een grote Git repository waar alle code in staat, van alle packages en applicaties. Je hebt dus één codebase waar je makkelijk doorheen kan zoeken en één pipeline configuratie zonder duplicatie. Mijn collega Timo heeft een blog geschreven over de voordelen van een monorepo, die kan je hier lezen.
Monorepo management is echter een vak apart en vereist de nodige kennis over de structuur, build configuratie en het afdwingen van de verschillende verwijzingen tussen de packages. Web components hebben helaas geen kant-en-klaar pakket zoals NX Workspaces liggen om een monorepo te beheren. Maar je kan wel hetzelfde bereiken met Yarn Workspaces of Lerna en een middagje pair programmen met een paar knappe koppen.
Mo’ Modularity
Voor de grotere setups met meerdere applicaties is het interessant om te kijken naar nog meer opsplitsing. Bijvoorbeeld met een dedicated design system: een verzamelbak van herbruikbare basiscomponenten.
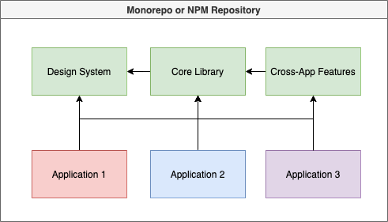
In deze situatie is het design system volledig losgekoppeld van elke mogelijke vorm van business logica. Dit geeft heel wat extra flexibiliteit: niet alle applicaties hoeven namelijk robuust opgezet te worden. Als je een kleine interne tool wil bouwen om wat data te transformeren, dan hoef je daar echt geen robuuste Application Core voor op te zetten. Gewoon een webpagina met een paar mooie componenten er op en een scriptje er achter is voldoende. Ook geeft het je veel ruimte om te experimenteren. Even een kleine PoC opzetten met een paar componenten is veel makkelijker gedaan als je niet vast hoeft te zitten aan een bepaalde applicatiestructuur.
Zorg er echter wel voor dat dit niet zorgt voor een wildgroei aan losse projectjes en experimenten. Op gegeven moment moet je de nuttige dingen consolideren en vastleggen in de design system, core library of feature library. Andere experimenten kan je beter archiveren en weghalen uit de codebase, anders zie je na een tijd de bomen door het bos niet meer.
Entering the Enterprise
Op een bepaald punt komt je op een codebase die zo groot is dat je enorm veel generieke features hebt om te delen tussen verschillende applicaties. Dat is het moment wanneer het interessant wordt om features ook in losse packages te zetten.
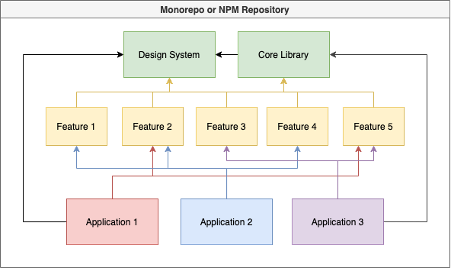
Elke feature als losse package. Klinkt als een hele operatie. En dat klopt, de hoeveelheid set-up die nodig is voor een structuur als deze is aanzienlijk. Maar de flexibiliteit die het je biedt is ongekend: applicaties kunnen uit een grote bak met features graaien en kiezen wat ze nodig hebben. Én omdat elke feature een losstaande package is in plaats van een grote feature library zie je ook heel duidelijk in je package.json wat de afhankelijkheden zijn van de applicatie.
Het diagram hierboven is natuurlijk een beetje misleidend. Dit ga je echt niet toepassen voor vijf gedeelde features. Dit wordt interessant op het moment dat je tientallen tot honderden generieke features hebt, met iets van drie of meer applicaties die ze gebruiken. Maar wanneer je het toepast kom je uiteindelijk uit op een soort microservices-achtige structuur, maar dan voor frontend applicaties. Teams kunnen onafhankelijk werken aan hun features en deze publiceren wanneer ze klaar zijn. Verschillende applicatieteams kunnen deze features dan op hun eigen tempo implementeren. Zelfsturend to the max dus.
No More Apps!
De vorige setup was nogal een wirwar van lijntjes die door elkaar lopen. En dat voor een diagram die versimpeld was en maar vijf gedeelde features heeft. In een groot landschap kan dit echter een enorme brei worden aan packages met allerlei afhankelijkheden die niet te traceren zijn. Ook zullen sommige applicaties maanden oude versies van features blijven gebruiken vanwege een gebrek aan (priori-)tijd om te updaten, waardoor de feature teams weer oude versies moeten onderhouden wanneer er bugs of incidenten zijn. Daarom heb ik nog een laatste diagram geschetst met een andere mogelijkheid om de complexiteit te reduceren.
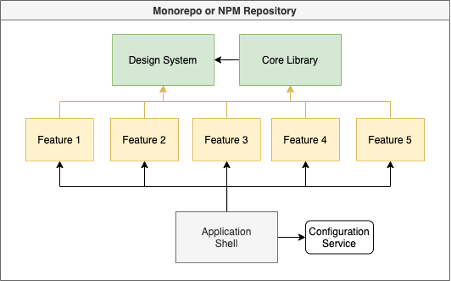
Met een Application Shell verwijder je het concept van een applicatie binnen je landschap. Er is één generieke applicatie die zo dom mogelijk is: er worden op basis van een configuratie (service) features ingeladen en op bepaalde pagina routes neergezet. Deze configuratie moet super flexibel zijn: je moet (virtuele) applicaties kunnen aanmaken op bepaalde URL’s, pagina’s binnen die applicatie kunnen bepalen én de features die op die pagina horen kunnen selecteren.
De features die op een pagina staan worden door de verschillende feature teams onderhouden. Deze kunnen de features zelf aanpassen en releasen wanneer zij dat geschikt vinden. In de feature configuratie kunnen ze dan aangeven welke applicatie welke versie van hun feature moet gebruiken. Daardoor kan je gedag zeggen tegen release trains van applicaties; teams zijn nu écht zelf end-to-end verantwoordelijk voor hun code. Micro-frontends op feature-niveau. Heuse Nanofrontends!
De aanloop naar deze architectuur is een enorm complex. De configuratie moet flexibel in te stellen zijn voor allerlei soorten scenario’s, zoals openbare, gesloten en interne applicaties. Het skelet met standaard styling van de pagina moet niet té generiek zijn om elke virtuele applicatie nog wel een unieke look & feel te kunnen geven. Features moeten een waterdichte set-up hebben waar er geen verassende afhankelijkheden zijn, en het liefste gebruiken ze ook allemaal dezelfde versie van het design system en andere generieke libraries om dubbele imports te voorkomen.
Daarnaast is het hele proces rondom deze architectuur ook een organisatorische uitdaging. Bedrijven die kiezen voor een landschap als deze zijn vaak van een dusdanig formaat dat je rekening moet houden met goedkeuringen, security checks en SLA’s op bepaalde functionaliteit. Dat hele model moet worden verwerkt in de workflow rondom het releasen van individuele features.
Toch brengt deze architectuur je heel erg veel. De Developer Experience zal enorm hoog liggen. Developers werken aan kleine, overzichtelijke features en bepalen zelf wanneer deze live gaan. Het gevoel van ownership ligt enorm hoog bij deze set-up, en je frontend developers worden heuse DevOps developers. Indirect doet dit ook veel met je engineering culture binnen je organisatie. Developers zijn veel autonomer en kunnen releasen wanneer het past binnen hun tijdlijn, en niet pas wanneer de volgende release train vertrekt. Dit zorgt voor een snellere time-to-market en meer tijd om aandacht te besteden aan de details, of het uitvoeren van experimentjes om te techniek vooruit te brengen.
Dit is dus verreweg de meest complexe architectuur om mee te beginnen. Maar ik vind dat hij wel goed scoort op de vier pijlers: een goede modulariteit, de testbaarheid ligt hoog omdat de verschillende lagen effectief gescheiden zijn, en de developer experience ligt hoog vanwege de autonomie en duidelijke afspraken qua structuur. Alleen de kwaliteit van de user experience is een vraagstuk. Omdat de applicatie erg flexibel is en features dynamisch inlaadt op basis van een configuratie zou het zomaar kunnen dat de performance erg laag ligt van de applicatie. Het is dus wél van belang dat er genoeg aandacht wordt besteed aan effectieve caching vanuit een CDN.
The Next Level
Goed, je weet nu wat over de principes, de techniek, de libraries, het ecosysteem en hoe je het groter aan kan pakken. Maar waar begin je? De kans is groot dat je al een bestaande frontend applicatie hebt. Of dat je de potentie van web components wel inziet voor bepaalde onderdelen van de applicatie, maar niet alles. Daarom ga ik je volgende week laten zien hoe je kan beginnen met web components. Hoe je web components laat samenwerken met een Vue, React of Angular applicatie. En wat de volgende stappen zijn om naar een toekomstbestendige frontend te reizen. Stay tuned!
Deelnemen aan een Web Components workshop met Wessel als trainer? Geef hier je interesse door. Ook beschikbaar voor developmentteams op locatie.
Inhoudsopgave
